Technical Blog
Connecting to SQL Server with MuleSoft AnyPoint 3.9
How to setup and test JDBC connections from SQL Server to MuleSoft AnyPoint 3.9. This article also covers configuration and performance considerations.

I usually blog about SQL Server, but I thought I’d share my experience of using SQL Server from MuleESB. If you haven’t used Mule before, it’s an open-source ESB, which also has a paid-for Enterprise version. I’ve been using it since 2015 and have been impressed with how quickly we can create quite complex applications. It’s swift, easy to use and free if you use the community version; I also have some experience with Java which helps. I tend to use Mule for applications that process web requests or when integrating with existing systems and SQL Server Integration Services (SSIS) for moving data around.
I’ve been working on a MuleESB program which needs to log millions of requests a day, and with the recent advancements in SQL Server, it’s now the obvious choice for storing almost any type of data. You can also run SQL Server 2017 on Linux, which will please a lot of Mule users.
Mule previously had an MSSQL connector, but that has been deprecated and replaced with the Generic Database Connector, which works with most JDBC drivers. To get started, we’ll need to download the latest driver from Microsoft and add it to our project. We can then configure the database using a standard connection string.
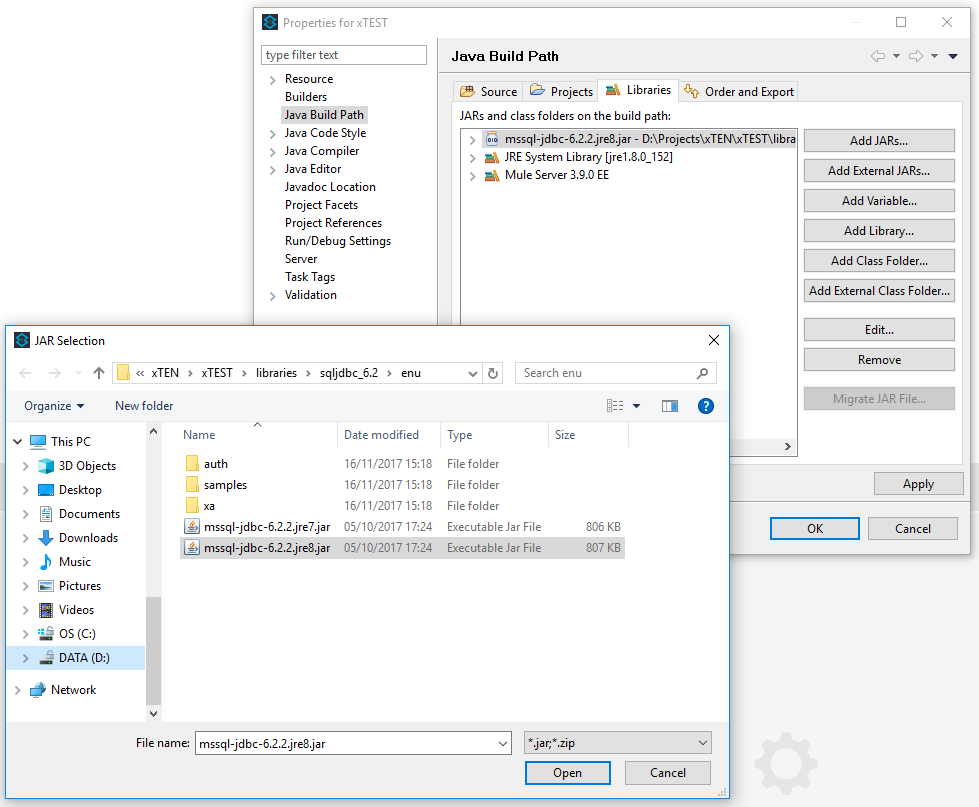
Download and add the JDBC driver
At the time of writing, the latest is JDBC 6.4; which you’ll need if you want to use SQL Server 2017 but my screenshots all reference JDBC 6.2.
Download Microsoft JDBC Driver for SQL Server
Add to your Mule Project using Add External JARS… and selecting either mssql-jdbc-6.2.2.jre7.jar or mssql-jdbc-6.2.2.jre8.jar; depending on your JRE.
Note: You’ll need JDBC 6.4 if you want a driver for JRE 9; you’ll also need Mule 4 as 3.9 doesn’t support Java 9.
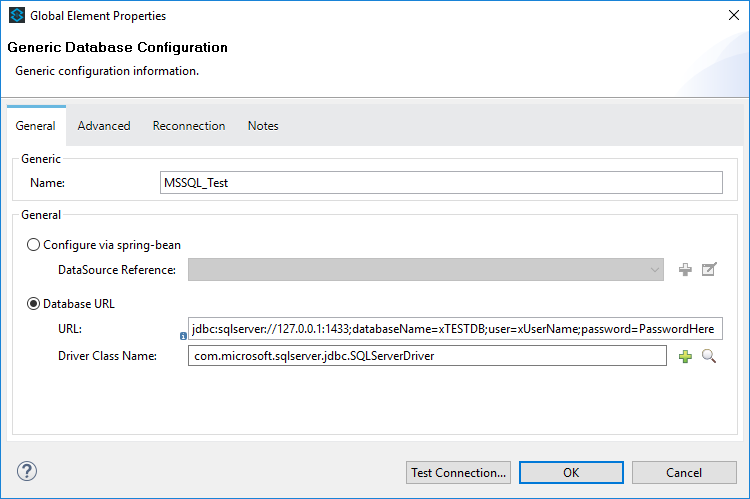
Configuring the Database Connector
The database connector is surprisingly easy to configure. We simply add a standard connection string and reference the JDBC driver, which is the same regardless of which JDBC driver you use. Aireforge has created an online connection string builder which you may find useful here.
Here’s an example which connects to a local instance which contains a database called TestDatabase. I’ve added the port, but this isn’t required unless it was changed from the default of 1433.
jdbc:sqlserver://127.0.0.1:1433;databaseName=TestDatabase;user=TestUser;password=reallySecure!;The above is fine for testing but I would suggest that you use parameters that are stored in a central configuration file to make your life easier. This will enable you to automatically set the environment settings using a local config file or manually change between Dev and Production by commenting on each section out. I would also advocate using an application name, as this will help you or the database team to identify your application; rather than it simply showing as a JDBC program.
jdbc:sqlserver://${mssql.server}:${mssql.port};databaseName=${mssql.database};user=${mssql.user};password=${mssql.password};Once this is set, you can store the following parameters in another mule config file. I tend to use global_properties.xml
<!-- Test Database Settings -->
<global-property name="mssql.server" value="127.0.0.1" doc:name="SQL Server Instance" />
<global-property name="mssql.port" value="1433" doc:name="SQL Server Port" />
<global-property name="mssql.database" value="TestDatabase" doc:name="Database Name" />
<global-property name="mssql.user" value="TestUser" doc:name="Username" />
<global-property name="mssql.password" value="reallySecure!" doc:name="Password" />
<!-- Production Database Settings
<global-property name="mssql.server" value="proddb1.xten.uk" doc:name="SQL Server Instance" />
<global-property name="mssql.port" value="1433" doc:name="SQL Server Port" />
<global-property name="mssql.database" value="LiveDB" doc:name="Database Name" />
<global-property name="mssql.user" value="MuleApp" doc:name="Username" />
<global-property name="mssql.password" value="superSecure!" doc:name="Password" />
-->Configuration and Performance Considerations
- By default, the maximum number of database connections is 5, unlike .NET where it’s 100. If you think you’ll need more, then make sure you set it higher.
- If you’ll be using the connection frequently; I would strongly recommend using a minimum connection pool size to lower the overhead on both Mule and SQL Server.
- If you’re using the standard port, then you don’t need to specify it but it doesn’t hurt and futureproofs your application.
- Only bother with a re-connection strategy if you really need the data. If it’s just logging, then consider throwing it away rather than overloading a server which may already be suffering from being overloaded.
- If you’re load balancing the connections, I would also suggest setting the Load Balance Timeout, otherwise, the connections will be sticky and won’t automatically balance after a server restart etc.
LoadBalanceTimeout=5000;- Again, I would set an application name to help when diagnosing issues.
- Consider enabling delayed durability when saving logging data as it will reduce the time in SQL Server and free up database connections quicker. I would also specify the specific stored procedure in use rather than forcing it for the entire database. With Delayed Durability, comes the possibility of data loss, so make sure you understand the risks.
- Consider using memory optimised tables for very busy applications, then process the data using a separate process. This could be called from Mule or via the SQL Server Agent. Again, if the data isn’t essential, I would opt for a SCHEMA_ONLY table; which is faster but you’ll lose the data should SQL Server restart. If this isn’t an option, you can use the default of SCHEMA_AND_DATA which will commit the data to disk.
- Use a stored procedure or parameterised queries when communicating with SQL Server as this will enable SQL Server to reuse execution plans.
- If you decide to use memory-optimized tables, consider a natively compiled stored procedure which will reduce the overhead of the queries and improve the performance.
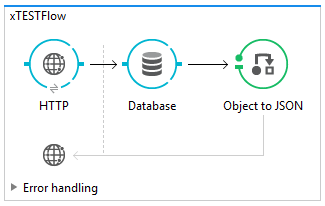
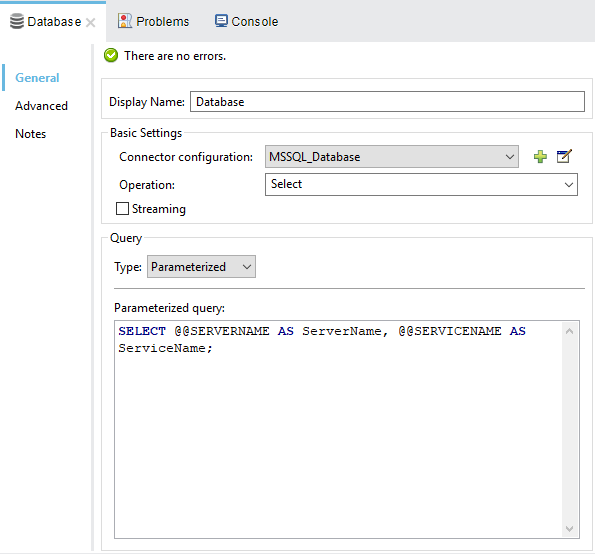
Quick Test
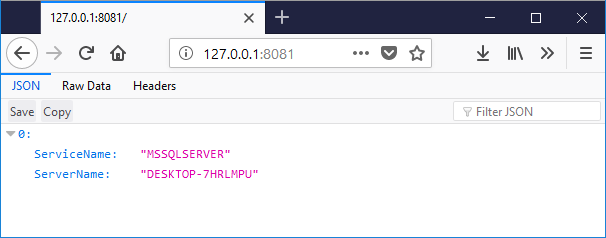
I’ve created a HTTP service listening on 8081 that will then connect to the database, retrieve the server and service name, and then return it as JSON.
Final thoughts
Microsoft has made the cheaper (or free) versions of SQL Server very powerful by allowing us to use features which were previously enterprise only. For me, it does everything I need from a database. In-memory tables that can handle thousands of updates a second, to large clustered columnstore tables that can handle real-time analytical queries that drive dashboards.
It would be nice to see the JTDS driver get more attention, as it’s much faster than ODBC but at the time of writing, doesn’t work with the latest versions of SQL Server and doesn’t have much documentation/support. Maybe Microsoft could release and maintain the JTDS driver in parallel to JDBC?
Utilising the cache scope could also prove quite powerful as it will reduce the resource requirements of SQL Server, whilst improving the performance of your Mule application. I’ll try to blog on this soon but feel free to pester me if I haven’t.
Further reading
Using the JDBC driver | Microsoft
Building the connection URL | Microsoft
Defining Durability for Memory-Optimized Objects | Microsoft
